在 Android 14(API level 34)及以上版本中,android.speech.SpeechRecognizer 提供了標準的語音識別能力,允許應用透過底層系統或指定的識別服務,將音訊輸入轉換為文字輸出。其主要功能包括:建立識別器實例、偵測系統是否支援識別、啟動/停止識別會話、取消或銷毀識別器,以及透過回呼介面接收識別結果和錯誤訊息。同時,Android 14 針對主執行緒呼叫、前台服務類型聲明等方面強化了行為約束,需要開發者註意避免 ANR 並正確配置服務類型。此外,API 在內網/雲端辨識、持續辨識及電量消耗等方面有侷限,需要根據應用場景選擇適當的實作方式。以下文件將從功能概覽、核心方法、回呼機制、權限與配置、Android 14 特性與限制五個部分進行介紹。
About 6 min
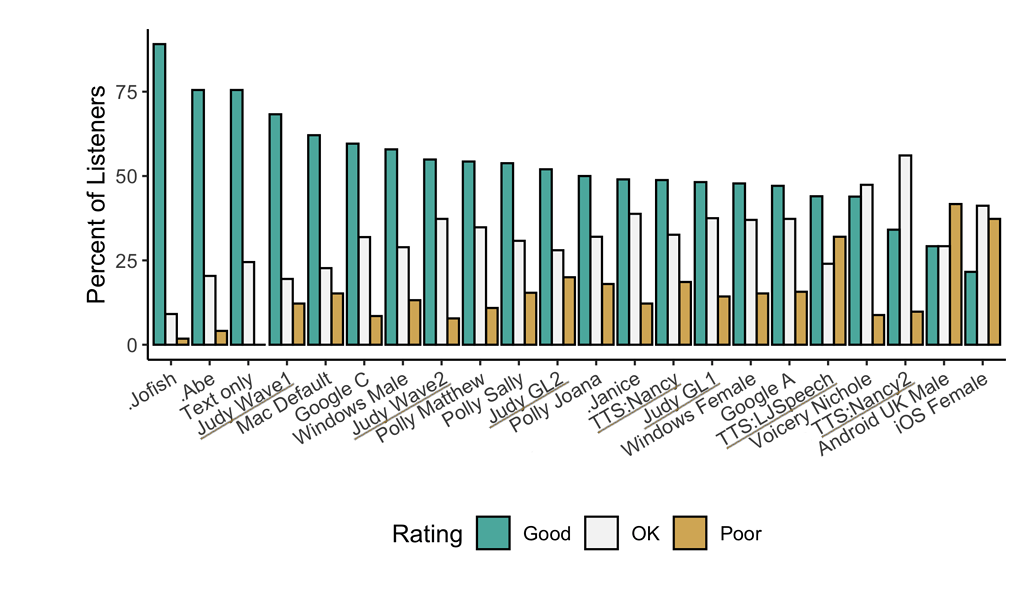 Underlined "TTS*" and "Judy*" are internal 🐸TTS models that are not released open-source. They are here to show the potential. Models prefixed with a dot (.Jofish .Abe and .Janice) are real human voices.
Underlined "TTS*" and "Judy*" are internal 🐸TTS models that are not released open-source. They are here to show the potential. Models prefixed with a dot (.Jofish .Abe and .Janice) are real human voices.