Whisper
Whisper
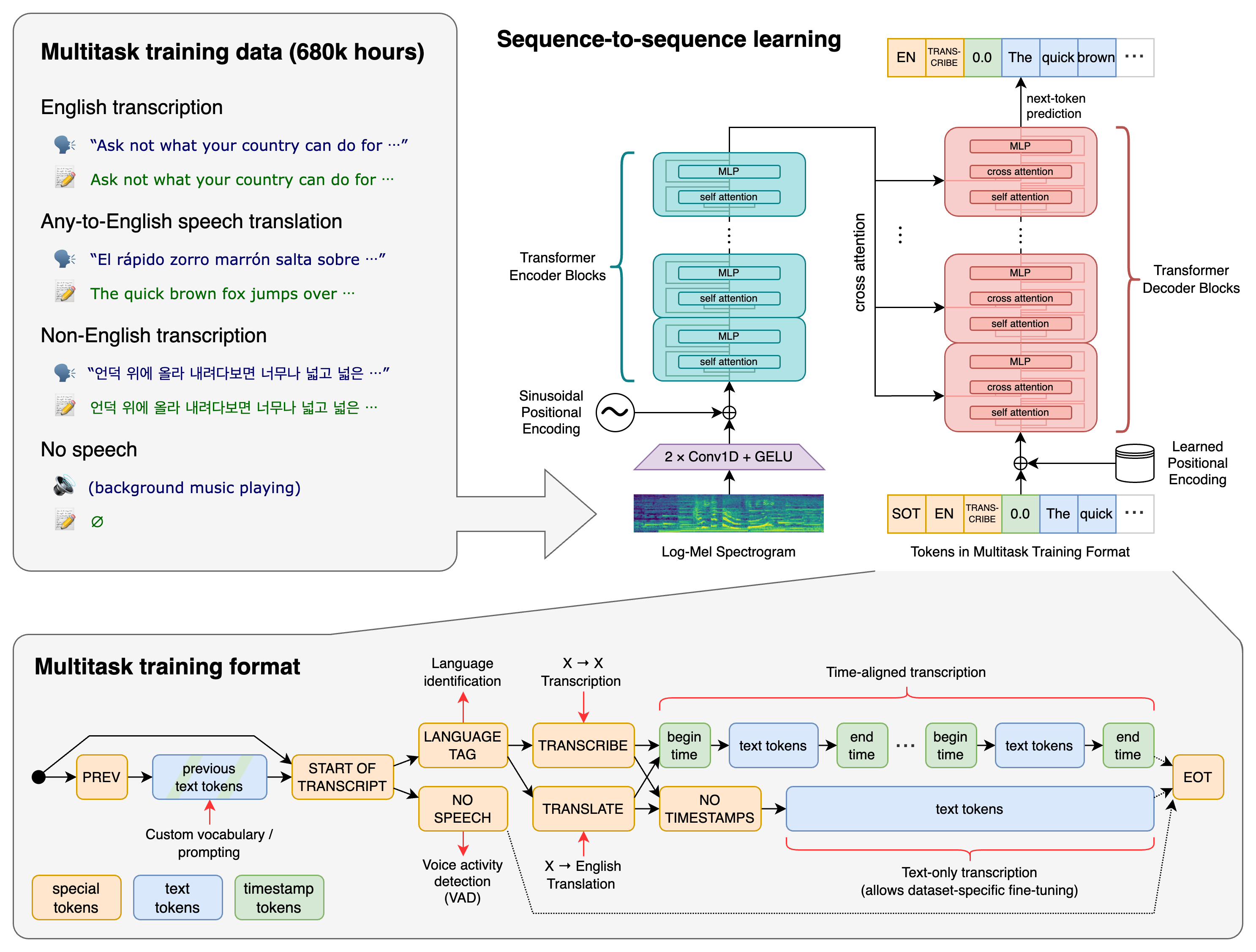
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio (680,000 hours of multilingual and multitask supervised data) and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
Approach
Available models and languages
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and inference speed relative to the large model; actual speed may vary depending on many factors including the available hardware.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
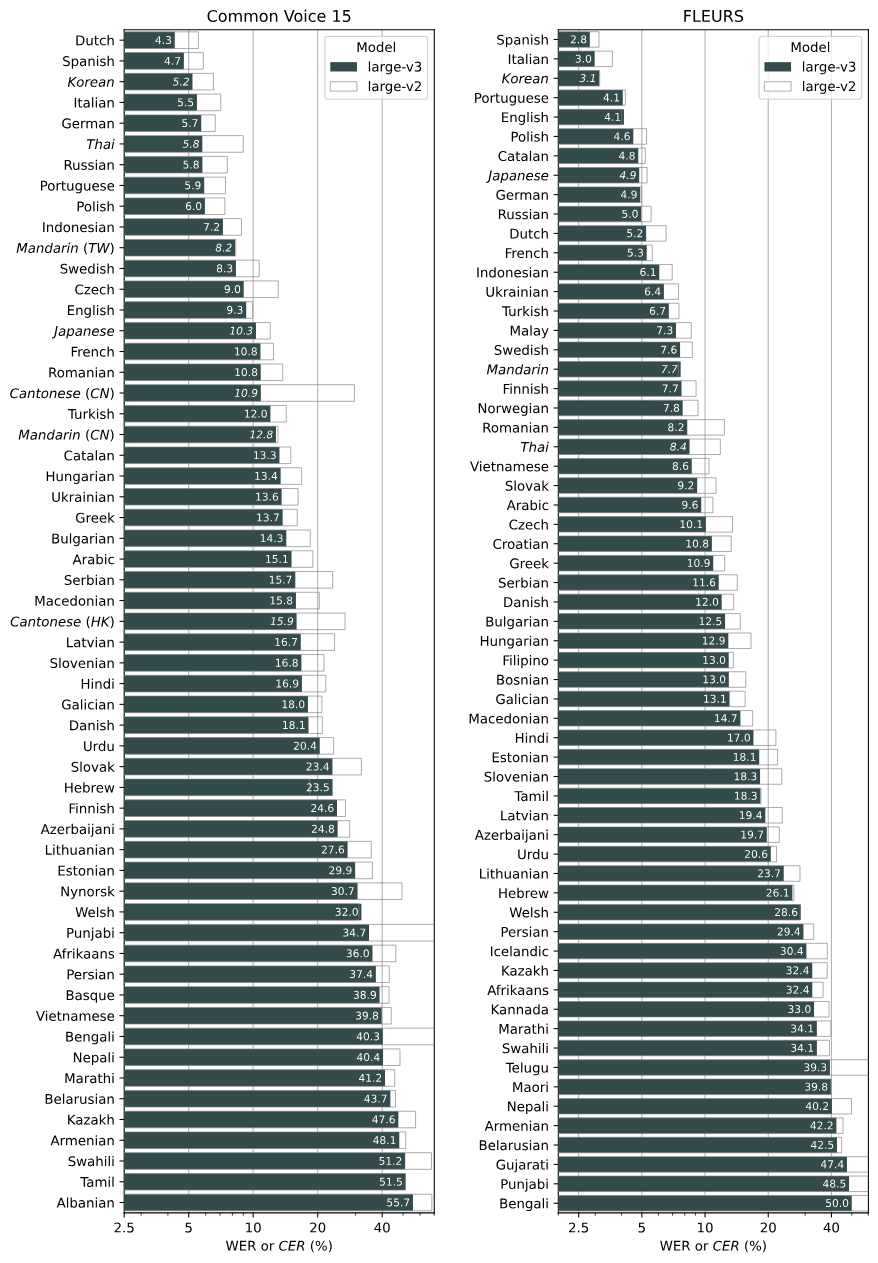
Whisper 的表現因語言而異。下圖顯示了按語言large-v3和模型的表現細分,使用在 Common Voice 15 和 Fleurs 資料集上評估的large-v2WER(單字錯誤率)或 CER(字元錯誤率,以斜體顯示)。
Python usage
It also requires the command-line tool ffmpeg to be installed on your system
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)Parameters
支持多個參數來調整其行為。以下是一些常見的參數及其用途:
- model : 模型名稱或路徑。Whisper 提供了多個預訓練模型,可以使用不同的大小(例如 "tiny", "base", "small", "medium", "large")來適應不同的計算能力和精度需求。
- language : 設置識別音頻時使用的語言。可以顯式指定語言代碼(如 "en" 表示英語)。
- task : 指定任務類型。可以是 "transcribe"(轉錄)或 "translate"(翻譯)。
- beam_size : 設置 beam search 的大小。較大的值可以提高轉錄的精度,但會增加計算時間。
- best_of : 對多次采樣結果進行排序,並選擇最佳結果。增加這個值會增加計算時間。
- temperature : 設置 softmax 溫度。較低的溫度會使模型輸出更確定的結果,較高的溫度會增加輸出的多樣性。
- condition_on_previous_text : 控制模型是否基於先前的文本上下文進行轉錄。
- fp16 : 控制是否使用半精度浮點數進行計算。如果 GPU 支持半精度計算,可以將其設置為 True 以加速計算。
import whisper
model = whisper.load_model("base")
audio_file = "audio.mp3"
audio = load_audio(audio_file)
result = model.transcribe(
audio,
language="en", # 語言
task="transcribe", # 任務類型
beam_size=5, # beam search 大小
best_of=5, # 最佳結果排序
temperature=0.7, # softmax 溫度
condition_on_previous_text=True, # 是否基於先前文本上下文
fp16=True # 使用半精度浮點數
)
# 輸出轉錄結果
print(result["text"])ValueError: beam_size and best_of can't be given together
Simply demo
- login github account
- upload your audio file
- set parameter
- run