WhisperX
About 5 min
WhisperX
WhisperX 是一個基於 OpenAI 開源語音識別模型 Whisper 的增強工具,專注於解決標準 Whisper 在語音轉文字 (ASR) 應用中的一些局限性,特別是 精確時間戳 和 說話人分離 功能。
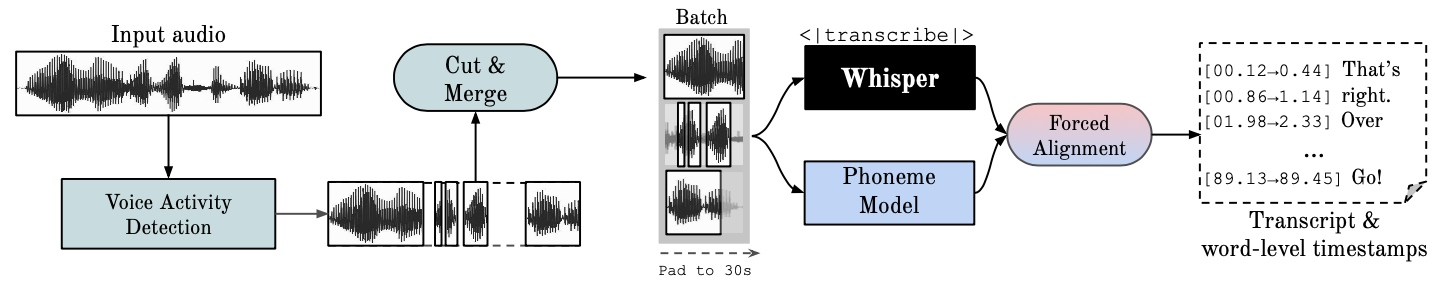
WhisperX 的功能與特點
1. 精確時間戳 (Word-level Alignment)
- 特點:
- Whisper 原生僅支持語句級別 (phrase-level) 的時間戳,這對於字幕生成等應用場景可能不夠精確。
- WhisperX 通過集成 音素對齊算法,提供逐字級別的時間戳,確保每個單詞的開始和結束時間更準確。
- 使用技術:
- 使用工具如
pyctcdecode和Aeneas,基於聲學特徵和語言模型進行對齊。
- 使用工具如
- 應用場景:
- 字幕生成(精確到每個單詞)。
- 時間敏感的語音轉文字應用(如語音檢索、索引構建)。
2. 說話人分離 (Speaker Diarization)
- 特點:
- 可以區分音頻中不同說話人的聲音,並標註每段話的說話人身份。
- 支持多說話人環境,如會議記錄、採訪音頻。
- 使用技術:
- 集成了 pyannote.audio,一個基於深度學習的說話人分離工具,能準確檢測和區分不同的說話人。
- 應用場景:
- 多人會議記錄。
- 客服通話分析(分析誰在說什麼)。
- 多人對話字幕生成。
3. 提高批量處理效率
- 特點:
- WhisperX 通過將長音頻分段並平行處理,顯著提升推理速度,特別是在大規模音頻處理場景中。
- 支持語音活動檢測 (Voice Activity Detection, VAD),自動跳過沉默部分,節省計算資源。
- 應用場景:
- 大型數據集的語音轉文字處理。
- 需要快速處理的大量音頻文件。
4. 支持多語言
- 與 Whisper 相同,WhisperX 繼承了其多語言支持特性,可識別 90+ 種語言。
- 自動語言檢測:可以處理不同語言的音頻,無需手動指定語言。
技術架構與工作流程
1. 模型選擇
- WhisperX 使用 OpenAI 的 Whisper 作為基礎模型,並根據需求選擇模型大小(如
tiny,base,large)。 - 模型的選擇影響準確性和運行速度。
2. 分段處理與語音活動檢測 (VAD)
- 音頻先通過 VAD 模塊分割為多個片段,過濾掉沉默部分,減少不必要的計算。
- 分段後的音頻被逐段處理,實現批量並行。
3. 精確時間戳對齊
- 使用 CTC (Connectionist Temporal Classification) 解碼技術,對音頻和文本進行逐字對齊。
- 為每個單詞生成開始和結束時間,保證字幕或語音檢索的精確性。
4. 說話人分離
- 基於 pyannote.audio 的深度學習模型進行說話人分離,生成不同說話人的對話段落。
WhisperX 的安裝與使用
1. 安裝
需要安裝 WhisperX 以及一些依賴項:
git clone https://github.com/m-bain/whisperX.git
pip install -r requirements.txt
pip install pyannote.audio
pip install ffmpeg2. 基本使用範例
以下是一個基本的 WhisperX 使用範例:
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx.load_model("large-v2", device, compute_type=compute_type)
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx.load_audio(audio_file)
result = model.transcribe(audio, batch_size=batch_size)
print(result["segments"]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a, metadata = whisperx.load_align_model(language_code=result["language"], device=device)
result = whisperx.align(result["segments"], model_a, metadata, audio, device, return_char_alignments=False)
print(result["segments"]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx.DiarizationPipeline(use_auth_token=YOUR_HF_TOKEN, device=device)
# add min/max number of speakers if known
diarize_segments = diarize_model(audio)
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx.assign_word_speakers(diarize_segments, result)
print(diarize_segments)
print(result["segments"]) # segments are now assigned speaker IDs應用場景與優勢
1. 媒體與娛樂
- 自動生成精確字幕(逐字時間戳)。
- 多人對話節目中的說話人標註。
2. 教育與會議
- 自動生成課堂或會議記錄,標明每位說話者的貢獻。
3. 語音檢索
- 建立語音索引,實現基於內容的檢索功能。
4. 客服與語音分析
- 客服電話錄音的多說話人分析與轉錄。
- 用於分析通話質量或提取有價值信息。
Whisper 和 WhisperX 差異
Whisper 和 WhisperX 是兩個相關但功能側重不同的工具,主要用於語音識別和處理。以下是它們的關鍵區別和功能對比:
功能對比
| 功能 | Whisper | WhisperX |
|---|---|---|
| 語音轉文字 (ASR) | ✅ 支持 | ✅ 支持 |
| 多語言支持 | ✅ 支持 | ✅ 支持 |
| 語音時間戳 (Phrase-level) | ✅ 支持 | ✅ 支持 |
| 精確時間戳 (Word-level) | ❌ 不支持 | ✅ 支持 |
| 說話人分離 | ❌ 不支持 | ✅ 支持(基於 pyannote.audio) |
| 批處理效率 | ❌ 效率較低 | ✅ 提升效率 |
| 配置難度 | ⭐ 簡單 | ⭐⭐⭐ 中等(需要額外配置) |
| 項目目標 | 通用語音識別 | 時間戳精度和說話人分離的應用場景 |
適用場景對比
| 場景 | Whisper | WhisperX |
|---|---|---|
| 標準語音轉文字 | ✅ 適合 | ✅ 適合 |
| 需要精確字幕時間戳 | ❌ 不適合 | ✅ 非常適合 |
| 分析多人對話,分離說話人 | ❌ 不適合 | ✅ 非常適合 |
| 大量音頻的批量處理 | ❌ 較慢 | ✅ 性能更好 |
選擇建議
- 如果你的需求是標準語音轉文字(不需要精確時間戳和說話人分離),使用 Whisper 即可,因為其配置簡單,適合一般應用場景。
- 如果你需要精確時間戳或說話人分離(例如製作字幕、多說話人會議記錄),WhisperX 是更好的選擇,儘管配置更複雜,但功能強大且更高效。