Coqui.ai TTS
About 3 min
Coqui.ai TTS
web demo
TTS Performance
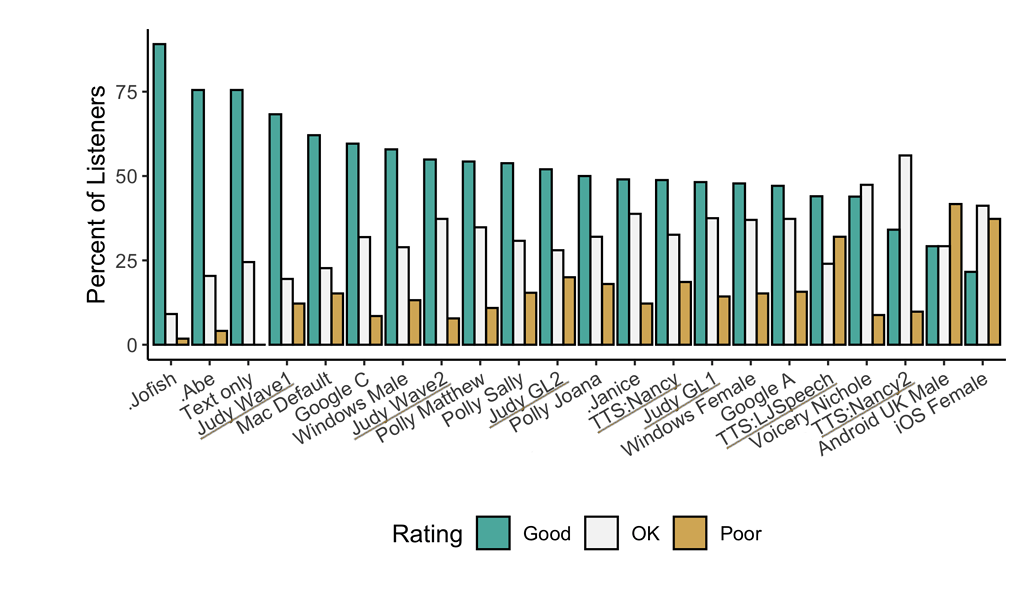 Underlined "TTS*" and "Judy*" are internal 🐸TTS models that are not released open-source. They are here to show the potential. Models prefixed with a dot (.Jofish .Abe and .Janice) are real human voices.
Underlined "TTS*" and "Judy*" are internal 🐸TTS models that are not released open-source. They are here to show the potential. Models prefixed with a dot (.Jofish .Abe and .Janice) are real human voices.
Features
- 高效能深度學習模型,用於文本到語音(Text2Speech)任務。
- 支援 Text2Spec 模型(Tacotron、Tacotron2、Glow-TTS、SpeedySpeech)。
- 語者編碼器(Speaker Encoder)計算語者嵌入(speaker embeddings)。
- 多種 Vocoder 模型(MelGAN、Multiband-MelGAN、GAN-TTS、ParallelWaveGAN、WaveGrad、WaveRNN)。
- 支援多語言 TTS。
Installation
🐸TTS is tested on Ubuntu 18.04 with python >= 3.9, < 3.12..
Using docker is relatively simple.
Dockerfile :
# COPY . .
# 使用官方的 Python 鏡像作為基礎鏡像
FROM python:3.9-slim
# 設定工作目錄
WORKDIR /app
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libsndfile1-dev \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --upgrade pip
RUN pip install TTS soundfile
# EXPOSE 5000
# 設定入口點(如果有需要的腳本)
# ENTRYPOINT ["python", "your_script.py"]
# 或進入互動式環境
CMD ["bash"]執行 :
docker build -t coqui-tts .docker run -it --rm -v /path/to/local/dir:/app/data coqui-tts- /path/to/local/dir -> 替換成自己的路徑
- with gpu ->
docker run -it --gpus all -v /path/to/local/dir:/app coqui-tts
unsupport in windows(ref)
Sample code
List available 🐸TTS models
models = TTS().list_models().list_models()
for model in models:
print(model)Running a multi-speaker and multi-lingual model
import torch
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to('cpu')
text = "Hello world."
wav = tts.tts(text="Hello world!", speaker_wav='speaker.wav', language="en")Example voice conversion
import torch
from TTS.api import TTS
tts = TTS(model_name="voice_conversion_models/multilingual/vctk/freevc24").to("cpu")
tts.voice_conversion_to_file(source_wav="a.wav", target_wav="b.wav", file_path="output.wav")Result
With tts_models/multilingual/multi-dataset/xtts_v2 model:
- eng text : Thanks for reading this article. I hope you learned something.
- zh text : 感謝您閱讀本文。我希望你學到了一些東西。
With voice_conversion_models/multilingual/vctk/freevc24 model:
differences between the major open source voice cloning projects
在這篇討論中,大家對於一些主要的開源語音克隆項目進行了比較,包括Coqui、Tortoise、Bark等。以下是整理出的主要重點和比較:
ElevenLabs
- 雖然質量最好,但不是開源的,也不是免費的。
Coqui
- 基於Tacotron2和VITS模型,支持多語言,可以自由調整語音,但需要大量數據和訓練。
- 開源但某些模型可能不允許商業使用。
- 被認為質量不如ElevenLabs,但因為是開源的且有商業API,可以進行微調和訓練。
Tortoise
- 使用Transformer技術,比較穩定,有些分支可以進行微調。
- 能夠在良好數據集下有優秀表現,但速度非常慢。
Bark
- 使用更現代的技術,潛力很大,但目前穩定性較差,訓練代碼不公開。
- 現階段可能不是最佳選擇。
其他開源項目
- XTTS-v2等項目提供了其他選擇,但目前這些項目的成熟度和性能與ElevenLabs等商業解決方案還有差距。
結論
- 開源項目如Coqui和Tortoise可以進行自訂和調整,但在質量和使用便捷性上尚無法與ElevenLabs等商業項目競爭。
- Bark和其他新興技術有潛力,但仍處於早期開發階段。
- 目前市場上對高質量語音克隆的需求仍未被完全滿足,尤其是開源領域。