🔍 主流程介紹
1. LangChain
About 7 min
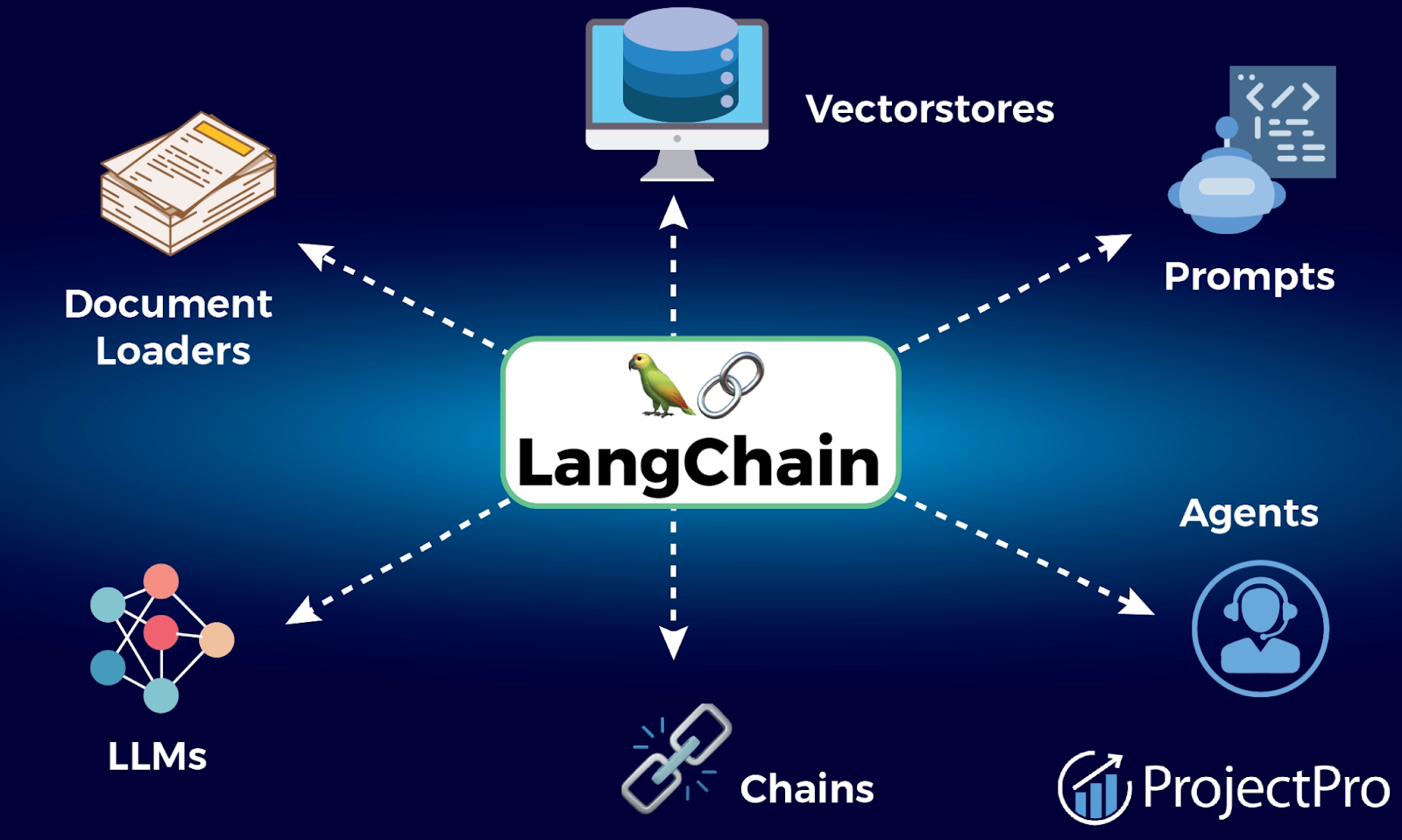
LangChain 是一套 用來建構以 LLM 為核心的應用(chatbot、RAG、Agent、自動化工作流) 的開放原始碼框架/編排層,提供模型介面、prompt 管理、chain/agent 模型、工具(tools)、記憶(memory)、向量資料庫(vectorstores)等標準化元件,讓你把 LLM 串成可重複、可測試、可部署的系統。(LangChain 文檔)
LangChain 本身 不是 AI 模型,而是幫你「用好模型」的框架。 它的主要價值是讓你能:
| 功能 | 說明 |
|---|---|
| 封裝 LLM | 對接各種大語言模型(OpenAI、Anthropic、HuggingFace、本地模型等) |
| 管理 Prompt | 用模板、變數、上下文生成一致的 prompt |
| 串接多步流程 (Chains) | 把「多個模型與步驟」組成完整任務 |
| 整合外部資料 (RAG) | 讓模型可以讀文件、查資料庫、問知識庫 |
| 使用工具 (Tools) | 讓模型能執行實際操作(API 呼叫、運算、控制系統) |
| 記憶 (Memory) | 讓模型記住對話上下文或長期資訊 |
| 決策與行動 (Agents) | 讓模型自己選擇何時用哪個工具完成任務 |
| 觀察與監控 (Tracing) | 追蹤模型每一步的輸入、輸出、成本 |
WhisperX 是一個基於 OpenAI 開源語音識別模型 Whisper 的增強工具,專注於解決標準 Whisper 在語音轉文字 (ASR) 應用中的一些局限性,特別是 精確時間戳 和 說話人分離 功能。
pyctcdecode 和 Aeneas,基於聲學特徵和語言模型進行對齊。Transformers 是一種基於注意力機制的深度學習架構,由 Vaswani 等人在 2017 年提出,最初設計用於自然語言處理(NLP)任務。其核心創新是引入了 Self-Attention 機制,使得模型可以在處理文本時同時考慮上下文。
Self-Attention 是一種深度學習中的注意力機制,能夠讓模型聚焦於輸入序列的不同部分,並且依據序列間的相關性調整輸出表示。這一機制在自然語言處理(NLP)和計算機視覺(CV)中有廣泛應用,尤其是 Transformer 架構的核心組件。
在 Self-Attention 中,每個輸入元素 被投影到三個向量空間:
以下是一些開源或已公開模型的AI摘要生成模型:
BART (Bidirectional and Auto-Regressive Transformers):
T5 (Text-To-Text Transfer Transformer):
<extra_id_0> token。PEGASUS:
LED (Longformer Encoder-Decoder):
GPT-2:
使用 Universal Sentence Encoder 來進行句子相似度和句子分類任務。 Universal Sentence Encoder 可以輕鬆取得句子層級的嵌入向量,並計算句子之間的語意相似度。
CLIP (Contrastive Language-Image Pre-Training) 是一種在各種(圖像,文本)對上訓練的神經網絡。它可以用自然語言指令來預測給定圖像最相關的文本片段,而不需要直接針對該任務進行優化,類似於GPT-2和GPT-3的零樣本能力。我們發現,CLIP在ImageNet上的“零樣本”表現與原始ResNet50相當,而未使用任何原始的128萬個標註示例,克服了計算機視覺中的多個主要挑戰。
Zero-shot classification 是一種自然語言處理任務,模型在訓練時使用一組標記示例,但能夠分類來自之前未見類別的新示例。
Zero-Shot Classification是一種預測模型在訓練期間未見過的類別的方法。這種方法利用預訓練的語言模型,可以視為轉移學習的一種形式,特別適用於標記數據量較小的情況。
Zero-Shot Learning(ZSL)是一種在訓練過程中未見過某些類別的樣本,但能夠在測試階段對這些類別進行分類的技術。這種學習方式通常依賴輔助信息來進行推斷。