Contrastive Language-Image Pretraining
About 4 min
Contrastive Language-Image Pretraining
CLIP (Contrastive Language-Image Pre-Training) 是一種在各種(圖像,文本)對上訓練的神經網絡。它可以用自然語言指令來預測給定圖像最相關的文本片段,而不需要直接針對該任務進行優化,類似於GPT-2和GPT-3的零樣本能力。我們發現,CLIP在ImageNet上的“零樣本”表現與原始ResNet50相當,而未使用任何原始的128萬個標註示例,克服了計算機視覺中的多個主要挑戰。
特點
- 多模態模型:能夠處理圖像和文本兩種輸入。
- 零樣本學習:能夠分類未見過的圖像類別,僅需提供相應的文本描述。
- 高效的特徵提取:可以將圖像和文本轉換為特徵向量,並計算它們之間的相似度。
CLIP的架構
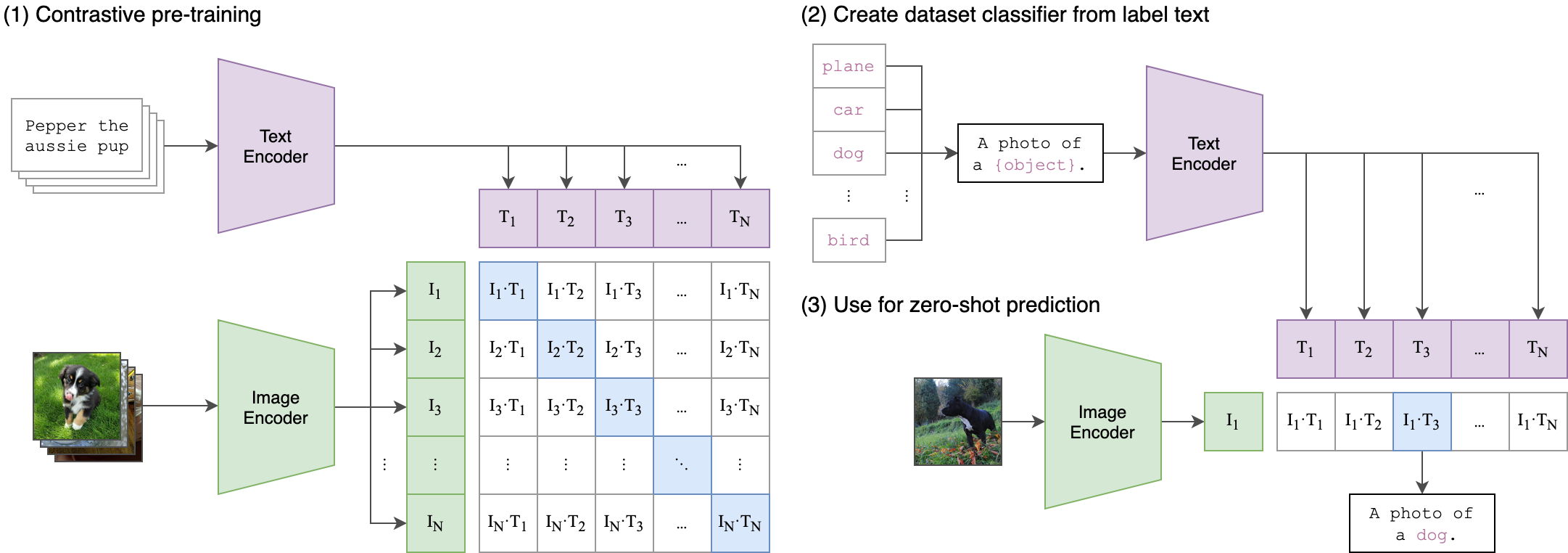
CLIP的架構主要由文本編碼器和圖像編碼器組成:
- 文本編碼器:使用Transformer模型處理自然語言,將文字轉換為數值表示。
- 圖像編碼器:使用神經網絡模型(如ResNet或Vision Transformer)處理圖像數據,將圖像轉換為數值表示。
訓練過程
CLIP的訓練過程包括以下步驟:
- 數據收集:使用包含4億對圖像和文本的數據集(WebImage Text)。
- 對比學習:通過計算圖像和文本特徵之間的相似性來訓練模型,最小化對比損失函數。
- 模型評估:在多個數據集上進行零樣本評估,顯示CLIP的廣泛適用性。
應用與優勢
- 圖像分類:CLIP能夠快速適應各種視覺分類任務,而無需額外的訓練數據。
- OCR:CLIP能夠在未經訓練的情況下執行OCR任務。
- 靈活性:CLIP可以根據給定的文本提示進行不同的分類任務。
限制與挑戰
- 抽象任務的挑戰:CLIP在計數和其他複雜任務上表現不佳。
- 對新圖像的泛化能力不足:CLIP在未見過的數據集上,表現可能不如專門訓練的模型。
- 敏感於文本提示:CLIP的性能可能受到文字描述的影響,需進行“提示工程”。
如何使用CLIP進行零樣本圖像分類
以下是使用CLIP進行零樣本圖像分類的示例代碼:
import torch
from PIL import Image
import clip
# 設置設備
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 加載並預處理圖片
image = preprocess(Image.open("path/to/your/image.jpg")).unsqueeze(0).to(device)
# 定義要分類的類別標籤
class_labels = ["cat", "dog", "car", "tree", "house"]
# 編碼圖片和文本描述
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(clip.tokenize(class_labels).to(device))
# 計算圖片和文本描述之間的相似度
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
# 打印結果
for label, prob in zip(class_labels, similarity[0]):
print(f"{label}: {prob.item():.4f}")結果示例
運行上述代碼後,你會得到每個類別標籤的概率。例如:
cat: 0.4523
dog: 0.1234
car: 0.0756
tree: 0.3012
house: 0.0475應用 : unsplash image search
精準圖片搜尋工具,來自OpenAI 最新的技術 CLIP。
為什麼 CLIP 搜圖能如此精準?
OpenAI 前不久推出的 DALL·E,主要能實現的功能就是可以按照文字描述、生成對應圖片。
而其呈現給我們的最終作品,其實是它生成大量圖片中的一部分,這之中其實也有排名、打分的篩選過程,這項任務,便由 CLIP 來完成:
只要圖片越是它看得懂、匹配度最高的作品,分數就會越高,排名也會越靠前。
改善描述
例如,描述一隻斑馬,可以用「馬的輪廓 + 虎的皮毛 + 熊貓的黑白」。這樣,網路就能從沒見過的數據資料中,找出「斑馬」的圖像。
Demo
Reference
- github-openai/CLIP
- HuggingFace-model
- github-Ayaa17/nlu-sample
- roboflow-what-is-zero-shot-classification
- toolify-文字圖像預訓練技術clip解析
- toolify-clip-連接文字和圖像-論文詳解
- csdn-CLIP:文本监督CV的预训练(2021)
- openai clip
- Hugging Face implementation of CLIP: for easier integration with the HF ecosystem
- buzzorange-unsplash image search
- 資料 : {(影像,文字)} : OpenAI 2021
- 用CLIP達成文字操弄/生成影像