Speaker Diarization 技術解析與應用
About 4 min
Speaker Diarization 技術解析與應用
1. 引言
1.1 什麼是 Speaker Diarization?
Speaker Diarization(說話人分離)是一種語音技術,旨在自動識別並區分一段音訊中不同說話人的語音片段,通常以「Who spoke when?」為核心問題。
1.2 重要性與應用場景
- 會議記錄與轉錄:自動標記參與者發言時間,提高文字紀錄的可讀性。
- 廣播與媒體監聽:自動區分主持人與來賓。
- 語音助理與客服分析:提升語音分析系統的準確性。
- 司法與監控:從電話錄音或監聽資料中識別說話人。
1.3 主要技術挑戰
- 說話人重疊(Speaker Overlap):當多個人同時說話時,區分語音片段較困難。
- 背景噪音與回音:環境音可能影響特徵提取。
- 未知說話人數:無法事先確定音訊中有多少個說話人。
- 變動的說話風格與語音變異:同一個人可能在不同情境下語音特徵變化。
2. Speaker Diarization 的工作流程
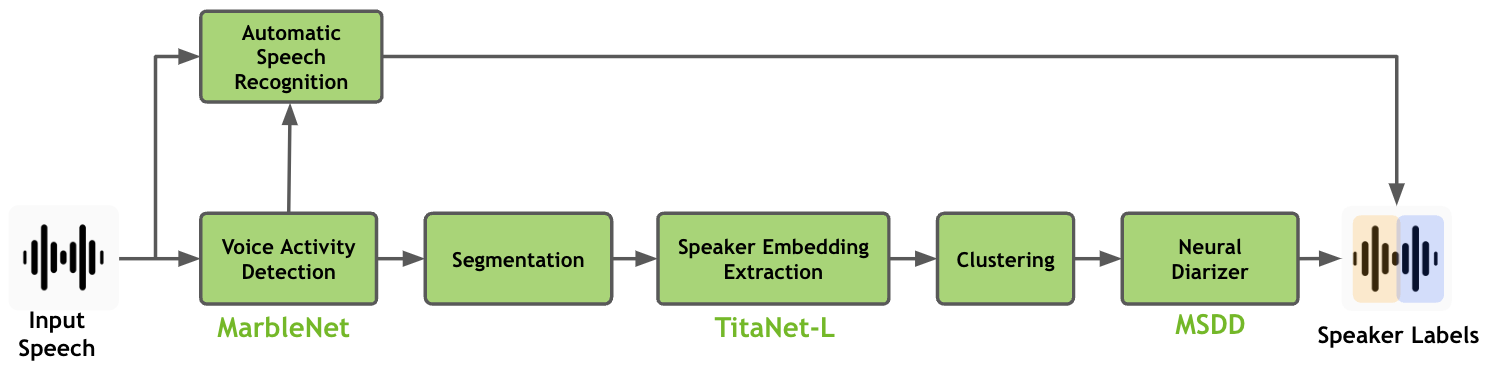
2.1 語音前處理
- 語音增強(Speech Enhancement):使用降噪技術(如 Spectral Subtraction)提高語音品質。
- 語音活動檢測(VAD, Voice Activity Detection):過濾掉靜音片段,減少無意義數據。
2.2 特徵提取(Feature Extraction)
- MFCC(Mel-Frequency Cepstral Coefficients):常用於語音識別的特徵。
- i-Vectors & x-Vectors:更現代的說話人嵌入技術,捕捉語音的時序資訊。
2.3 語音分群(Clustering)
- K-means:將特徵向量分成 K 個群組。
- Spectral Clustering:透過圖論方法來進行分群。
- Agglomerative Hierarchical Clustering(AHC):使用層次分群方法來識別不同說話人。
2.4 語者標識與後處理
- PLDA(Probabilistic Linear Discriminant Analysis):提高說話人分群準確度。
- 後處理校正:透過 Viterbi decoding 進一步修正邊界。
3. 常見方法與開源框架
3.1 傳統方法
- GMM-HMM(高斯混合模型 - 隱馬可夫模型)
- i-Vector + PLDA
3.2 深度學習方法
- DNN(深度神經網絡):用於特徵提取與語音分群。
- LSTM(長短時記憶網絡):擅長處理時序數據。
- Transformer-based Models:利用注意力機制提升說話人嵌入準確度。
3.3 開源工具
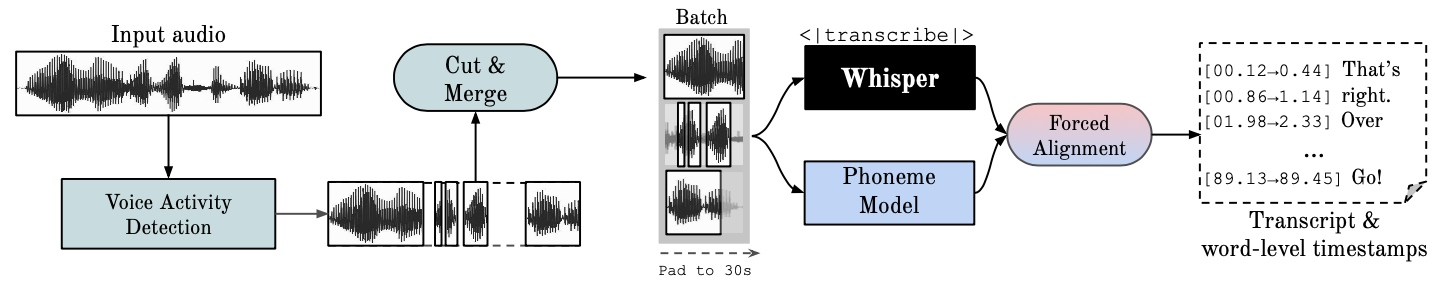
4. 近期發展與挑戰
4.1 Speaker Overlap Detection
現代系統正在研究如何區分同時說話的多個語者,避免將重疊語音視為單一人。
4.2 語者嵌入技術的進化
- x-Vectors 改進:比 i-Vectors 更適合深度學習模型。
- ECAPA-TDNN:一種強化語者嵌入的方法。
4.3 低資源環境的 Speaker Diarization
- 小型模型的開發,使其能夠在邊緣設備上運行。
5. 應用案例與實作
5.1 Google Meet、Otter.ai 的應用
- Google Meet 利用 ASR + Diarization 來標記發言者。
- Otter.ai 創建逐字稿並標示說話人。
5.2 Kaldi + Pyannote 實作示例
# 下載 Kaldi
git clone https://github.com/kaldi-asr/kaldi.git
# 安裝 pyannote-audio
pip install pyannote.audiofrom pyannote.audio.pipelines import SpeakerDiarization as SD
pipeline = SD.from_pretrained("pyannote/speaker-diarization")
result = pipeline("audio.wav")
print(result)5.3 可用的優化策略
- 使用更好的 VAD 模型來減少雜訊。
- 透過後處理修正說話人邊界。
- 結合語音識別(ASR)來提高分群準確率。
6. 實作 real-time speaker diarization with ASR
Ayaa17/live-transcribe-py (private repository)
If you would like to access, please contact me.
Reference
- nvidia - Speaker Diarization
- NVIDIA NeMo
- m-bain/whisperX
- speechbrain
- speechbrain/vad-crdnn-libriparty
- pyannote/pyannote-audio
- pyannote/segmentation-3.0
- pyannote.audio paper
- Rumeysakeskin/Speaker-Verification
- speaker diarization 是如何實現的呢? (公式)
- One speaker segmentation model to rule them all
- 李宏毅 Speaker Verification
- paperswithcode - Speaker Diarization
- Unsupervised Speaker Diarization using Sparse Optimization
- Sound classification with YAMNet
- Speaker diarization: Libraries & APIs for developers
- Speaker Diarization Explained: Choosing the Best Method
- Speaker Diarization
- Who spoke when: Choosing the right speaker diarization tool